Shader Generation¶
This book will examine how to set up MaterialX for code generation. This book covers the generateshader.py script provided as part of the core distribution.
Topics covered:
- Shading language 'target's
- Module / library organization
- Setting up generators and generation contexts
- Real world units and color management
- Discovering "renderable" items, and generating code
- Extracting source code
Details behind code generation, generation options, introspection / reflection, and input binding is covered as part of rendering.
Background on code generation can be found here.
Code Generation Modules / Libraries¶
For the Python distribution, each code generator resides in a separate module in the MaterialX package.
The name of each module is of the form:
PyMaterialXGen<target>
where target is the code generation target written in camel-case.
All target names start with gen and then the shading language name:
gen<target>
For example, the target for the OSL shading language is genosl, with the module's postfix string being GenOsl.
The variants for GLSL include: genglsl and genessl, which reside in a single module with postfix string GenGlsl.
The C++ library equivalent to the module is named:
MaterialXGen<target>
This is basically the same as the Python module but without the Py prefix.
The module PyMaterialxShader contains the base support for all code generators. In the code below this module as well as modules for all targets are imported.
import sys, os, subprocess
import MaterialX as mx
import MaterialX.PyMaterialXGenShader as mx_gen_shader
import MaterialX.PyMaterialXGenGlsl as mx_gen_glsl
import MaterialX.PyMaterialXGenOsl as mx_gen_osl
import MaterialX.PyMaterialXGenMdl as mx_gen_mdl
print('MaterialX Version', mx.getVersionString())
# Version check
from mtlxutils.mxbase import *
supportsMSL = haveVersion(1, 38, 7)
if supportsMSL:
import MaterialX.PyMaterialXGenMsl as mx_gen_msl
print('Have required version for MSL')
MaterialX Version 1.39.2 Have required version for MSL
Setup¶
The basic setup requires that a document is created, the standard libraries are loaded, and the document containing the elements to generate code for to be present.
For the purposes of showing formatted results we use the
IPythonpackage to be able to outputMarkdownfrom Python code.
from IPython.display import display_markdown
Additional modules can be imported to support functionality such as code validation.
Code Validation¶
For GLSL, ESSL, and Vulkan languages glslangValidator can be used for syntax and compilation validation. It is installed using vcpkg and is run as part of the CI process. For OSL and MDL: olsc and mdlc compilers are used respectively.
The generateshader.py script supports passing in a external program as an argument. The source code passed to this program for validation.
The utility function from that script has been extracted out and is included below as an example.
def validateCode(sourceCodeFile, codevalidator, codevalidatorArgs):
if codevalidator:
cmd = codevalidator + ' ' + sourceCodeFile
if codevalidatorArgs:
cmd += ' ' + codevalidatorArgs
print('----- Run Validator: '+ cmd)
try:
output = subprocess.check_output(cmd, stderr=subprocess.STDOUT)
result = output.decode(encoding='utf-8')
except subprocess.CalledProcessError as out:
return (out.output.decode(encoding='utf-8'))
return ""
Exception Handling¶
In the following code, a document is first created and then a sample file which defines a "marble" material is read in.
Note that MaterialX throws exceptions when encountering errors instead of keeping track of status code. There are some specific exceptions which provide additional information beyond the regular exception information.
It is always prudent to catch exceptions including checking of custom exceptions provided for file I/O, code generation and rendering.
In this example a "file missing" exception may be returned if the file cannot be read.
The possible Exception types are defined in the API documentation. In Python, the exception name is the same as the C++ class name.
# Read in MaterialX file
#
inputFilename = 'data/standard_surface_marble_solid.mtlx'
doc = mx.createDocument()
try:
mx.readFromXmlFile(doc, inputFilename)
valid, msg = doc.validate()
if not valid:
raise mx.Exception('Document is invalid')
print('Read in valid file "'"%s"'" for code generation.' % inputFilename)
except mx.ExceptionMissing as err:
print('File %s could not be loaded: "' % inputFilename, err, '"')
except mx.Exception as err:
print('File %s fail to load properly: "' % inputFilename, err, '"')
Read in valid file "data/standard_surface_marble_solid.mtlx" for code generation.
Implementations¶
The standard library includes both definitions as well as implementations for each shading language.
The stdlib, stdlib, and bxdf folders contain definitions and any corresponding node graph and
source code implementations.
The sub-folders starting with gen contain per-target source code implementations.
import pkg_resources
def getLibraryFoldersString(root='libraries', showMTLXFiles=True, showSourceFiles=False):
'''
Scan the MaterialX library folder and print out the folder structure
'''
folderString = ''
files = pkg_resources.resource_listdir('MaterialX', root)
for f in files:
if not mx.FilePath(f).getExtension():
folderString += '+--%s\n' % f
fpath = root+'/'+f
if pkg_resources.resource_isdir('MaterialX', fpath):
subfiles = pkg_resources.resource_listdir('MaterialX', fpath)
for sf in subfiles:
sfPath = mx.FilePath(fpath+'/'+sf)
extension = sfPath.getExtension()
if extension and showMTLXFiles:
folderString += '|\t|--%s\n' % sf
elif not extension:
if sf == 'genglsl':
folderString += '|\t+--%s <-- e.g. target genglsl implementations reside here\n' % sf
else:
folderString += '|\t+--%s\n' % sf
sfpath = fpath+'/'+sf
if pkg_resources.resource_isdir('MaterialX', sfpath):
subsubfiles = pkg_resources.resource_listdir('MaterialX', sfpath)
for ssf in subsubfiles:
extension = mx.FilePath(ssf).getExtension()
if extension and showSourceFiles:
print('show source : ssf')
folderString += '|\t \t+--%s\n' % ssf
elif not extension:
folderString += '|\t \t+--%s\n' % ssf
# If not last file, add a line break
#if f != files[-1]:
# folderString += '|\n'
#folderString += '|\n'
return folderString
folderString = getLibraryFoldersString('libraries', False, False)
folderString = '<p>Library Folders:</p><pre>\n' + folderString + "\n</pre>"
display_markdown(folderString, raw=True)
Library Folders:
+--bxdf | +--lama | +--translation +--cmlib +--lights | +--genglsl <-- e.g. target genglsl implementations reside here | +--genmsl +--nprlib | +--genglsl <-- e.g. target genglsl implementations reside here | +--genmdl | +--genmsl | +--genosl +--pbrlib | +--genglsl <-- e.g. target genglsl implementations reside here | +--lib | +--genmdl | +--genmsl | +--genosl | +--lib +--stdlib | +--genglsl <-- e.g. target genglsl implementations reside here | +--lib | +--genmdl | +--genmsl | +--lib | +--genosl | +--include | +--lib +--targets
As this code is required for code generation to occur, the standard libraries folder must be read in.
The libraries folder can be examined as part of the Python package as of 1.38.7. Below is a simple utility to traverse and print out the folders found. This starts where the site packages are located (as returned using site.getsitepackages()). This works either whether called from a virtual environment or not.
import site
def printPaths(rootPath):
"Print a 'tree' of paths given a root path"
outputStrings = []
for dirpath, dirs, files in os.walk(rootPath):
testpath = dirpath.removeprefix(rootPath)
path = testpath.split(os.sep)
comment = ''
if len(path) > 1:
if path[len(path)-1].startswith('gen'):
comment = ' ( _Root of target specific implementations_ )'
indent = (len(path)-1)*' '
outputString = indent + '- ' + os.path.basename(dirpath) + comment + '\n'
outputStrings.append(outputString)
display_markdown(outputStrings, raw=True)
packages = site.getsitepackages()
for package in packages:
libraryPath = mx.FilePath(package + '/MaterialX/libraries')
if os.path.exists(libraryPath.asString()):
printPaths(libraryPath.asString())
break
- libraries
- bxdf
- lama
- translation
- cmlib
- lights
- genglsl ( Root of target specific implementations )
- genmsl ( Root of target specific implementations )
- nprlib
- genglsl ( Root of target specific implementations )
- genmdl ( Root of target specific implementations )
- genmsl ( Root of target specific implementations )
- genosl ( Root of target specific implementations )
- pbrlib
- genglsl ( Root of target specific implementations )
- lib
- genmdl ( Root of target specific implementations )
- genmsl ( Root of target specific implementations )
- genosl ( Root of target specific implementations )
- lib
- genglsl ( Root of target specific implementations )
- stdlib
- genglsl ( Root of target specific implementations )
- lib
- genmdl ( Root of target specific implementations )
- genmsl ( Root of target specific implementations )
- lib
- genosl ( Root of target specific implementations )
- include
- lib
- genglsl ( Root of target specific implementations )
- targets
- bxdf
Implementations are of the type Implementation.
# Load in standard libraries, and include an definitions local to the input file
stdlib = mx.createDocument()
searchPath = mx.getDefaultDataSearchPath()
searchPath.append(os.path.dirname(inputFilename))
libraryFolders = mx.getDefaultDataLibraryFolders()
try:
libFiles = mx.loadLibraries(libraryFolders, searchPath, stdlib)
doc.importLibrary(stdlib)
print('Version: %s. Loaded %s standard library definitions' % (mx.getVersionString(), len(doc.getNodeDefs())))
except mx.Exception as err:
print('Failed to load standard library definitions: "', err, '"')
Version: 1.39.2. Loaded 780 standard library definitions
The getImplementations() API is used to get a list of Implementation references. Even though the total number
of implementations seem large, only the source code for a specific generator are used at any given time.
# Get list of all implementations
implmentations = doc.getImplementations()
if implmentations:
print('Read in %d implementations' % len(implmentations))
Read in 1628 implementations
Implementation Targets¶
Every non-nodegraph implementation must specify a target that it supports.
A target name is used to identify shading languages and their variants. The naming convention is:
gen<language name>
These are represented as a TargetDef.
The target identifiers are loaded in as part of the standard library, and these can be queried by
looking for elements of category targetdef. For convenience, a list of available targets can be retrieved from a
document using the getTargetDefs() API.
However, at time of writing, this is missing from the Python API. Thus a simple utility function is provided here.
# The targetdef type and support API does not currently exist so cannot be used.
#doc.getTargetDefs()
#doc.getChildOfType(mx.TargetDef)
# Utility that basically does what doc.getTargetDefs() does.
# Matching the category can be used in lieu to testing for the class type.
def getTargetDefs(doc):
targets = []
for element in doc.getChildren():
if element.getCategory() == 'targetdef':
targets.append(element.getName())
return targets
foundTargets = getTargetDefs(doc)
for target in foundTargets:
implcount = 0
# Find out how many implementations we have
for impl in implmentations:
testtarget = target
if target == 'essl':
testtarget = 'genglsl'
if impl.getTarget() == testtarget:
implcount = implcount + 1
print('Found target identifier:', target, 'with', implcount, 'source implementations.')
Found target identifier: essl with 518 source implementations. Found target identifier: genglsl with 518 source implementations. Found target identifier: genmdl with 528 source implementations. Found target identifier: genmsl with 63 source implementations. Found target identifier: genosl with 517 source implementations.
Code Generators¶
Generator Creation¶
Every code generator must have a target identifier to indicate which shading langauge / variant it supports.
A language version can be used to distinguish a variant if appropriate (e.g. ESSL is distinguishable this way)
It is recommended that all new generators have a unique target name.
Currently there is no "registry" for generators by target so the user must know before hand which generators exist and
go through all generators to find one with the appropriate target to use.
Targets themselves can be "inherited" which is reflected in the inheritance hierarchy for generators.
For example the essl (ESSL) target inherits from the genglsl (GLSL) target as does the corresponding generators.
Inheritance is generally used to specialize code generation to handle shading language variations.
For a list of generators and their derivations see documentation for the base class ShaderGenerator
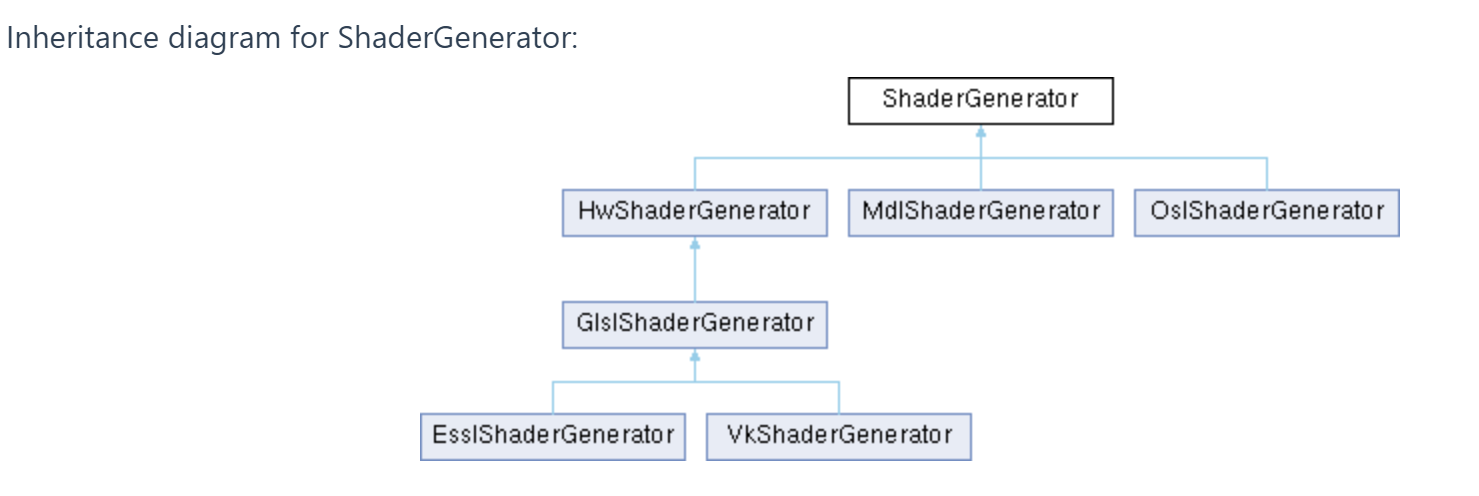
Note that Vulkan has the same target as genglsl, but has it's own generator. Also that the Metal generator will only show up
in the Mac build of documentation.
Integrations are free to create custom generators. Some notable existing generators include those used to support USD HDStorm, VEX, and Arnold OSL.
Any such generator can be instantiated and use the same generation process as described here.
For this example, we will show how all the the generators can be created, but will only produce OSL code via an OslShaderGenerator generator. This can be found in the PyMaterialXGenOsl Python submodule and corresponding MaterialXGenOsl library in C++.
# Create all generators
generators = []
generators.append(mx_gen_osl.OslShaderGenerator.create())
generators.append(mx_gen_mdl.MdlShaderGenerator.create())
generators.append(mx_gen_glsl.EsslShaderGenerator.create())
generators.append(mx_gen_glsl.VkShaderGenerator.create())
if supportsMSL:
generators.append(mx_gen_msl.MslShaderGenerator.create())
# Create a dictionary based on target identifier
generatordict = {}
for gen in generators:
generatordict[gen.getTarget()] = gen
# Choose generator to use based on target identifier
language = 'mdl'
target = 'genmdl'
if language == 'osl':
target = 'genosl'
elif language == 'mdl':
target = 'genmdl'
elif language == 'essl':
target = 'essl'
elif language == 'msl':
target = 'genmsl'
elif language in ['glsl', 'vulkan']:
target = 'genglsl'
print(generatordict.keys())
#test_language = 'mdl'
test_shadergen = generatordict['genmdl']
#print('Find code generator for target:', test_shadergen.getTarget(), ' for language:', test_language, ". Version:", test_shadergen.getVersion())
shadergen = generatordict[target]
print('Use code generator for target:', shadergen.getTarget(), ' for language: ', language)
dict_keys(['genosl', 'genmdl', 'essl', 'genglsl', 'genmsl']) Use code generator for target: genmdl for language: mdl
Generator Contexts¶
A "generation context" is required to be created for each generator instance. This is represented by a
GenContext structure.
This context provides a number of settings and options to be used for code generation.
For simplicity, we will only point out the minimal requirements. This includes providing a search path to where source code implementations can be found. Any number of paths can be added using the registerSourceCodeSearchPath() function, on the context. The search order is first to last path added.
Adding the path to the libraries folder is sufficient to find the source code for standard library definitions found in sub-folders. If the user has custom definitions in other locations, the root of those locations should be added.
# Create a context for a generator
context = mx_gen_shader.GenContext(shadergen)
# Register a path to where implmentations can be found.
context.registerSourceCodeSearchPath(searchPath)
Color Management¶
Color management is used to ensure that input colors are interpreted properly via shader code.
A "color management system" cab be created and specified to be used by a shader generator. During code generation, additional logic is emitted into the shader source code via the system.
Usage of such as system during code generation is optional, as some renderers perform color management on input values and images before binding them to shading code.
Color management systems need to be derived from the base API interface ColorManagementSystem). A "default" system is provided
as part of the MaterialX distribution.
It is necessary to indicate which target shading language code when instantiating the color management system. Naturally specifying a non-matching target will inject incompatible code.
The setup steps are:
- Create the system. In this example the "default" system is created with the
targetbeing specified at creation time. - Setting where the library of definitions exists for the system. In this case the main document which contains the standard library is specified.
- Setting the color management system on the generator. If it is not set or cleared then no color management will occur during code generation.
# Create default CMS
cms = mx_gen_shader.DefaultColorManagementSystem.create(shadergen.getTarget())
# Indicate to the CMS where definitions can be found
cms.loadLibrary(doc)
# Indicate to the code generator to use this CMS
shadergen.setColorManagementSystem(cms)
cms = shadergen.getColorManagementSystem()
if cms:
print('Set up CMS: %s for target: %s'
% (cms.getName(), shadergen.getTarget()))
Set up CMS: default_cms for target: genmdl
Real World Units¶
To handle real-world unit specifiers a "unit system" should be instantiated and associated with the generator. The API interface is a UnitSystem which definitions.
By default a unit system does not know how to perform any conversions. This is provided by a
UnitConverterRegistry which contains a list of convertors.
Currently MaterialX supports convertors for converting linear units: distance, and angle.
The corresponding API interface is LinearUnitConverter.
# Create unit registry
registry = mx.UnitConverterRegistry.create()
if registry:
# Get distance and angle unit type definitions and create a linear converter for each
distanceTypeDef = doc.getUnitTypeDef('distance')
if distanceTypeDef:
registry.addUnitConverter(distanceTypeDef, mx.LinearUnitConverter.create(distanceTypeDef))
angleTypeDef = doc.getUnitTypeDef('angle')
if angleTypeDef:
registry.addUnitConverter(angleTypeDef, mx.LinearUnitConverter.create(angleTypeDef))
print('Created unit converter registry')
Created unit converter registry
As with a color management system the location of implementations and the registry need to be set on a unit system. The unit system can then be set on the generator.
# Create unit system, set where definitions come from, and
# set up what registry to use
unitsystem = mx_gen_shader.UnitSystem.create(shadergen.getTarget())
unitsystem.loadLibrary(stdlib)
unitsystem.setUnitConverterRegistry(registry)
if unitsystem:
print('Set unit system on code generator')
shadergen.setUnitSystem(unitsystem)
Set unit system on code generator
This sets up how to perform unit conversions, but does not specify what unis the scene geometry is using. This can be specified as in an "options" structure found on the context.
The API interface is: GenOptions.
# Set the target scene unit to be `meter` on the context options
genoptions = context.getOptions()
genoptions.targetDistanceUnit = 'meter'
Finding Elements to Render¶
There are a few utilities which are included to find elements which are "renderable":
- The findRenderableElement() utility can be used in general to find these.
- Another possible utility is to find only material nodes using
getMaterialNodes()or - Shader nodes by looking for nodes of type
SURFACE_SHADER_TYPE_STRINGin a document.
For this example, the first "renderable" found is used.
# Look for renderable nodes
nodes = mx_gen_shader.findRenderableElements(doc, False)
print('Found: %d renderables' % len(nodes))
if not nodes:
nodes = doc.getMaterialNodes()
if not nodes:
nodes = doc.getNodesOfType(mx.SURFACE_SHADER_TYPE_STRING)
node = None
if nodes:
node = nodes[0]
print('Found node to render: ', node.getName())
Found: 1 renderables Found node to render: Marble_3D
Generating Code¶
After all of this setup, code can now be generated.
- First a
createValidName()utility is called to ensure that the shader name produced is valid. - Then the generator's generate() interface is called with this name, the "renderable" element, and the generation context. Note that derived classes override
generate()to perform custom generation.
Upon success a new Shader instance is created. Note that this is a special interface used to keep track of an entire shader. This instance can be inspected to extract information required for rendering.
shader = None
nodeName = node.getName() if node else ''
if nodeName:
shaderName = mx.createValidName(nodeName)
try:
genoptions = context.getOptions()
genoptions.shaderInterfaceType = mx_gen_shader.ShaderInterfaceType.SHADER_INTERFACE_COMPLETE
shader = shadergen.generate(shaderName, node, context)
except mx.Exception as err:
print('Shader generation errors:', err)
if shader:
print('Succeeded in generating code for shader "%s" code from node "%s"' % (shaderName, nodeName))
else:
print('Failed to generate code for shader "%s" code from node "%s"' % (shaderName, nodeName))
Succeeded in generating code for shader "Marble_3D" code from node "Marble_3D"
Generated Code¶
For hardware languages like GLSL, vertex, and pixel shader code is generated. OSL and MDL only produce pixel shader code. To complete this example the pixel shader code is queried from the Shader and shown below.
Code can be queried via the getSourceCode() interface with an argument indicating which code to return. The code returned can be directly compiled and used by a renderer.
It is at this point in the generateshader.py script that validation is performed. (This will not be shown here.)
pixelSource = ''
vertexSource = ''
if shader:
errors = ''
# Use extension of .vert and .frag as it's type is
# recognized by glslangValidator
if language in ['glsl', 'essl', 'vulkan']:
vertexSource = shader.getSourceCode(mx_gen_shader.VERTEX_STAGE)
text = '<details><summary>Vertex Shader For: "' + nodeName + '"</summary>\n\n' + '```cpp\n' + vertexSource + '```\n' + '</details>\n'
display_markdown(text , raw=True)
pixelSource = shader.getSourceCode(mx_gen_shader.PIXEL_STAGE)
text = '<details><summary>Pixel Shader For: "' + nodeName + '"</summary>\n\n' + '```cpp\n' + pixelSource + '```\n' + '</details>\n'
display_markdown(text , raw=True)
Pixel Shader For: "Marble_3D"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
color NG_convert_float_color3
(
float in1 = 0.000000
)
{
color combine_out = color( in1,in1,in1 );
return combine_out;
}
material NG_standard_surface_surfaceshader_100
(
float base = 0.800000,
color base_color = color(1.000000, 1.000000, 1.000000),
float diffuse_roughness = 0.000000,
float metalness = 0.000000,
float specular = 1.000000,
color specular_color = color(1.000000, 1.000000, 1.000000),
float specular_roughness = 0.200000,
float specular_IOR = 1.500000,
float specular_anisotropy = 0.000000,
float specular_rotation = 0.000000,
float transmission = 0.000000,
color transmission_color = color(1.000000, 1.000000, 1.000000),
float transmission_depth = 0.000000,
color transmission_scatter = color(0.000000, 0.000000, 0.000000),
float transmission_scatter_anisotropy = 0.000000,
float transmission_dispersion = 0.000000,
float transmission_extra_roughness = 0.000000,
float subsurface = 0.000000,
color subsurface_color = color(1.000000, 1.000000, 1.000000),
color subsurface_radius = color(1.000000, 1.000000, 1.000000),
float subsurface_scale = 1.000000,
float subsurface_anisotropy = 0.000000,
float sheen = 0.000000,
color sheen_color = color(1.000000, 1.000000, 1.000000),
float sheen_roughness = 0.300000,
float coat = 0.000000,
color coat_color = color(1.000000, 1.000000, 1.000000),
float coat_roughness = 0.100000,
float coat_anisotropy = 0.000000,
float coat_rotation = 0.000000,
float coat_IOR = 1.500000,
float3 coat_normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal()),
float coat_affect_color = 0.000000,
float coat_affect_roughness = 0.000000,
float thin_film_thickness = 0.000000,
float thin_film_IOR = 1.500000,
float emission = 0.000000,
color emission_color = color(1.000000, 1.000000, 1.000000),
color opacity = color(1.000000, 1.000000, 1.000000),
bool thin_walled = false,
float3 normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal()),
float3 tangent = state::transform_vector(state::coordinate_internal, state::coordinate_world, state::texture_tangent_u(0))
)
= let
{
float2 coat_roughness_vector_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_roughness, mxp_anisotropy:coat_anisotropy);
float coat_tangent_rotate_degree_out = coat_rotation * 360.000000;
color metal_reflectivity_out = base_color * base;
color metal_edgecolor_out = specular_color * specular;
float coat_affect_roughness_multiply1_out = coat_affect_roughness * coat;
float tangent_rotate_degree_out = specular_rotation * 360.000000;
float transmission_roughness_add_out = specular_roughness + transmission_extra_roughness;
color subsurface_color_nonnegative_out = math::max(subsurface_color, 0.000000);
float coat_clamped_out = math::clamp(coat, 0.000000, 1.000000);
color subsurface_radius_scaled_out = subsurface_radius * subsurface_scale;
float subsurface_selector_out = float(thin_walled);
color base_color_nonnegative_out = math::max(base_color, 0.000000);
color coat_attenuation_out = math::lerp(color(1.000000, 1.000000, 1.000000), coat_color, coat);
float one_minus_coat_ior_out = 1.000000 - coat_IOR;
float one_plus_coat_ior_out = 1.000000 + coat_IOR;
color emission_weight_out = emission_color * emission;
color opacity_luminance_out = materialx::stdlib_1_9::mx_luminance_color3(opacity);
float3 coat_tangent_rotate_out = materialx::stdlib_1_9::mx_rotate3d_vector3(mxp_in:tangent, mxp_amount:coat_tangent_rotate_degree_out, mxp_axis:coat_normal);
auto artistic_ior_result = materialx::pbrlib_1_9::mx_artistic_ior(mxp_reflectivity:metal_reflectivity_out, mxp_edge_color:metal_edgecolor_out);
float coat_affect_roughness_multiply2_out = coat_affect_roughness_multiply1_out * coat_roughness;
float3 tangent_rotate_out = materialx::stdlib_1_9::mx_rotate3d_vector3(mxp_in:tangent, mxp_amount:tangent_rotate_degree_out, mxp_axis:normal);
float transmission_roughness_clamped_out = math::clamp(transmission_roughness_add_out, 0.000000, 1.000000);
float coat_gamma_multiply_out = coat_clamped_out * coat_affect_color;
float coat_ior_to_F0_sqrt_out = one_minus_coat_ior_out / one_plus_coat_ior_out;
float opacity_luminance_float_out = materialx::stdlib_1_9::mx_extract_color3(opacity_luminance_out, 0);
float3 coat_tangent_rotate_normalize_out = math::normalize(coat_tangent_rotate_out);
float coat_affected_roughness_out = math::lerp(specular_roughness, 1.000000, coat_affect_roughness_multiply2_out);
float3 tangent_rotate_normalize_out = math::normalize(tangent_rotate_out);
float coat_affected_transmission_roughness_out = math::lerp(transmission_roughness_clamped_out, 1.000000, coat_affect_roughness_multiply2_out);
float coat_gamma_out = coat_gamma_multiply_out + 1.000000;
float coat_ior_to_F0_out = coat_ior_to_F0_sqrt_out * coat_ior_to_F0_sqrt_out;
float3 coat_tangent_out = materialx::stdlib_1_9::mx_ifgreater_vector3(coat_anisotropy, 0.000000, coat_tangent_rotate_normalize_out, tangent);
float2 main_roughness_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_affected_roughness_out, mxp_anisotropy:specular_anisotropy);
float3 main_tangent_out = materialx::stdlib_1_9::mx_ifgreater_vector3(specular_anisotropy, 0.000000, tangent_rotate_normalize_out, tangent);
float2 transmission_roughness_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_affected_transmission_roughness_out, mxp_anisotropy:specular_anisotropy);
color coat_affected_subsurface_color_out = math::pow(subsurface_color_nonnegative_out, coat_gamma_out);
color coat_affected_diffuse_color_out = math::pow(base_color_nonnegative_out, coat_gamma_out);
float one_minus_coat_ior_to_F0_out = 1.000000 - coat_ior_to_F0_out;
color emission_color0_out = NG_convert_float_color3(one_minus_coat_ior_to_F0_out);
material metal_bsdf_out = materialx::pbrlib_1_9::mx_conductor_bsdf(mxp_weight:1.000000, mxp_ior:artistic_ior_result.mxp_ior, mxp_extinction:artistic_ior_result.mxp_extinction, mxp_roughness:main_roughness_out, mxp_thinfilm_thickness:thin_film_thickness, mxp_thinfilm_ior:thin_film_IOR, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx);
material transmission_bsdf_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:1.000000, mxp_tint:transmission_color, mxp_ior:specular_IOR, mxp_roughness:transmission_roughness_out, mxp_thinfilm_thickness:0.000000, mxp_thinfilm_ior:1.500000, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_T, mxp_base:material(), mxp_top_weight:1.000000);
material translucent_bsdf_out = materialx::pbrlib_1_9::mx_translucent_bsdf(mxp_weight:1.000000, mxp_color:coat_affected_subsurface_color_out, mxp_normal:normal);
material subsurface_bsdf_out = materialx::pbrlib_1_9::mx_subsurface_bsdf(mxp_weight:1.000000, mxp_color:coat_affected_subsurface_color_out, mxp_radius:subsurface_radius_scaled_out, mxp_anisotropy:subsurface_anisotropy, mxp_normal:normal);
material selected_subsurface_bsdf_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:translucent_bsdf_out, mxp_bg:subsurface_bsdf_out, mxp_mix:subsurface_selector_out);
material diffuse_bsdf_out = materialx::pbrlib_1_9::mx_oren_nayar_diffuse_bsdf(mxp_weight:base, mxp_color:coat_affected_diffuse_color_out, mxp_roughness:diffuse_roughness, mxp_normal:normal, mxp_energy_compensation:false);
material subsurface_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:selected_subsurface_bsdf_out, mxp_bg:diffuse_bsdf_out, mxp_mix:subsurface);
material sheen_layer_out = materialx::pbrlib_1_9::mx_sheen_bsdf(mxp_weight:sheen, mxp_color:sheen_color, mxp_roughness:sheen_roughness, mxp_normal:normal, mxp_base:subsurface_mix_out);
material transmission_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:transmission_bsdf_out, mxp_bg:sheen_layer_out, mxp_mix:transmission);
material specular_layer_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:specular, mxp_tint:specular_color, mxp_ior:specular_IOR, mxp_roughness:main_roughness_out, mxp_thinfilm_thickness:thin_film_thickness, mxp_thinfilm_ior:thin_film_IOR, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_R, mxp_base:transmission_mix_out, mxp_top_weight:1.000000);
material metalness_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:metal_bsdf_out, mxp_bg:specular_layer_out, mxp_mix:metalness);
material thin_film_layer_attenuated_out = materialx::pbrlib_1_9::mx_multiply_bsdf_color3(mxp_in1:metalness_mix_out, mxp_in2:coat_attenuation_out);
material coat_layer_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:coat, mxp_tint:color(1.000000, 1.000000, 1.000000), mxp_ior:coat_IOR, mxp_roughness:coat_roughness_vector_out, mxp_thinfilm_thickness:0.000000, mxp_thinfilm_ior:1.500000, mxp_normal:coat_normal, mxp_tangent:coat_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_R, mxp_base:thin_film_layer_attenuated_out, mxp_top_weight:1.000000);
material emission_edf_out = materialx::pbrlib_1_9::mx_uniform_edf(mxp_color:emission_weight_out);
material coat_tinted_emission_edf_out = materialx::pbrlib_1_9::mx_multiply_edf_color3(mxp_in1:emission_edf_out, mxp_in2:coat_color);
material coat_emission_edf_out = materialx::pbrlib_1_9::mx_generalized_schlick_edf(mxp_color0:emission_color0_out, mxp_color90:color(0.000000, 0.000000, 0.000000), mxp_exponent:5.000000, mxp_base:coat_tinted_emission_edf_out);
material blended_coat_emission_edf_out = materialx::pbrlib_1_9::mx_mix_edf(mxp_fg:coat_emission_edf_out, mxp_bg:emission_edf_out, mxp_mix:coat);
material shader_constructor_out = materialx::pbrlib_1_9::mx_surface(mxp_bsdf: coat_layer_out, mxp_edf: blended_coat_emission_edf_out, mxp_opacity: opacity_luminance_float_out, mxp_thin_walled: false);
}
in material(shader_constructor_out);
export material Marble_3D
(
uniform mx_coordinatespace_type geomprop_Nworld_space = mx_coordinatespace_type_world
[[
materialx::core::origin("Nworld")
]],
uniform mx_coordinatespace_type geomprop_Tworld_space = mx_coordinatespace_type_world
[[
materialx::core::origin("Tworld")
]],
uniform int geomprop_Tworld_index = 0
[[
materialx::core::origin("Tworld")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
float bias_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]],
float power_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/noise_power")
]],
color color_mix_fg = color(0.100000, 0.100000, 0.300000)
[[
materialx::core::origin("NG_marble1/base_color_2")
]],
color color_mix_bg = color(0.800000, 0.800000, 0.800000)
[[
materialx::core::origin("NG_marble1/base_color_1")
]],
float SR_marble1_base = 1.000000
[[
materialx::core::origin("SR_marble1/base")
]],
float SR_marble1_diffuse_roughness = 0.000000
[[
materialx::core::origin("SR_marble1/diffuse_roughness")
]],
float SR_marble1_metalness = 0.000000
[[
materialx::core::origin("SR_marble1/metalness")
]],
float SR_marble1_specular = 1.000000
[[
materialx::core::origin("SR_marble1/specular")
]],
color SR_marble1_specular_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/specular_color")
]],
float SR_marble1_specular_roughness = 0.100000
[[
materialx::core::origin("SR_marble1/specular_roughness")
]],
float SR_marble1_specular_IOR = 1.500000
[[
materialx::core::origin("SR_marble1/specular_IOR")
]],
float SR_marble1_specular_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/specular_anisotropy")
]],
float SR_marble1_specular_rotation = 0.000000
[[
materialx::core::origin("SR_marble1/specular_rotation")
]],
float SR_marble1_transmission = 0.000000
[[
materialx::core::origin("SR_marble1/transmission")
]],
color SR_marble1_transmission_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/transmission_color")
]],
float SR_marble1_transmission_depth = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_depth")
]],
color SR_marble1_transmission_scatter = color(0.000000, 0.000000, 0.000000)
[[
materialx::core::origin("SR_marble1/transmission_scatter")
]],
float SR_marble1_transmission_scatter_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_scatter_anisotropy")
]],
float SR_marble1_transmission_dispersion = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_dispersion")
]],
float SR_marble1_transmission_extra_roughness = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_extra_roughness")
]],
float SR_marble1_subsurface = 0.400000
[[
materialx::core::origin("SR_marble1/subsurface")
]],
color SR_marble1_subsurface_radius = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/subsurface_radius")
]],
float SR_marble1_subsurface_scale = 1.000000
[[
materialx::core::origin("SR_marble1/subsurface_scale")
]],
float SR_marble1_subsurface_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/subsurface_anisotropy")
]],
float SR_marble1_sheen = 0.000000
[[
materialx::core::origin("SR_marble1/sheen")
]],
color SR_marble1_sheen_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/sheen_color")
]],
float SR_marble1_sheen_roughness = 0.300000
[[
materialx::core::origin("SR_marble1/sheen_roughness")
]],
float SR_marble1_coat = 0.000000
[[
materialx::core::origin("SR_marble1/coat")
]],
color SR_marble1_coat_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/coat_color")
]],
float SR_marble1_coat_roughness = 0.100000
[[
materialx::core::origin("SR_marble1/coat_roughness")
]],
float SR_marble1_coat_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/coat_anisotropy")
]],
float SR_marble1_coat_rotation = 0.000000
[[
materialx::core::origin("SR_marble1/coat_rotation")
]],
float SR_marble1_coat_IOR = 1.500000
[[
materialx::core::origin("SR_marble1/coat_IOR")
]],
float SR_marble1_coat_affect_color = 0.000000
[[
materialx::core::origin("SR_marble1/coat_affect_color")
]],
float SR_marble1_coat_affect_roughness = 0.000000
[[
materialx::core::origin("SR_marble1/coat_affect_roughness")
]],
float SR_marble1_thin_film_thickness = 0.000000
[[
materialx::core::origin("SR_marble1/thin_film_thickness")
]],
float SR_marble1_thin_film_IOR = 1.500000
[[
materialx::core::origin("SR_marble1/thin_film_IOR")
]],
float SR_marble1_emission = 0.000000
[[
materialx::core::origin("SR_marble1/emission")
]],
color SR_marble1_emission_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/emission_color")
]],
color SR_marble1_opacity = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/opacity")
]],
bool SR_marble1_thin_walled = false
[[
materialx::core::origin("SR_marble1/thin_walled")
]]
)
= let
{
material backsurfaceshader = material();
material displacementshader = material();
float3 geomprop_Nworld_out1 = materialx::stdlib_1_9::mx_normal_vector3(mxp_space:geomprop_Nworld_space);
float3 geomprop_Tworld_out1 = materialx::stdlib_1_9::mx_tangent_vector3(mxp_space:geomprop_Tworld_space, mxp_index:geomprop_Tworld_index);
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + bias_in2;
float power_out = math::pow(bias_out, power_in2);
color color_mix_out = math::lerp(color_mix_bg, color_mix_fg, power_out);
material SR_marble1_out = NG_standard_surface_surfaceshader_100(SR_marble1_base, color_mix_out, SR_marble1_diffuse_roughness, SR_marble1_metalness, SR_marble1_specular, SR_marble1_specular_color, SR_marble1_specular_roughness, SR_marble1_specular_IOR, SR_marble1_specular_anisotropy, SR_marble1_specular_rotation, SR_marble1_transmission, SR_marble1_transmission_color, SR_marble1_transmission_depth, SR_marble1_transmission_scatter, SR_marble1_transmission_scatter_anisotropy, SR_marble1_transmission_dispersion, SR_marble1_transmission_extra_roughness, SR_marble1_subsurface, color_mix_out, SR_marble1_subsurface_radius, SR_marble1_subsurface_scale, SR_marble1_subsurface_anisotropy, SR_marble1_sheen, SR_marble1_sheen_color, SR_marble1_sheen_roughness, SR_marble1_coat, SR_marble1_coat_color, SR_marble1_coat_roughness, SR_marble1_coat_anisotropy, SR_marble1_coat_rotation, SR_marble1_coat_IOR, geomprop_Nworld_out1, SR_marble1_coat_affect_color, SR_marble1_coat_affect_roughness, SR_marble1_thin_film_thickness, SR_marble1_thin_film_IOR, SR_marble1_emission, SR_marble1_emission_color, SR_marble1_opacity, SR_marble1_thin_walled, geomprop_Nworld_out1, geomprop_Tworld_out1);
material Marble_3D_out = materialx::stdlib_1_9::mx_surfacematerial(mxp_surfaceshader: SR_marble1_out, mxp_backsurfaceshader: backsurfaceshader, mxp_displacementshader: displacementshader);
material finalOutput__ = Marble_3D_out;
}
in material(finalOutput__);
Shader Refection¶
It is often required to be able to get information about the shader uniforms / arguments. These uniforms are organized into "blocks" such that each block's uniforms has a corresponding ShaderPort which can be inspected. The general term for provide additional information is shader refection.
The following utility function is used to extract information about the shader uniforms. Integrations can customize to create their own reflection structures.
def getPortPath(inputPath, doc):
'''
Find any upstream interface input which maps to a given path.
'''
if not inputPath:
return inputPath, None
input = doc.getDescendant(inputPath)
if input:
# Redirect to interface input if it exists.
interfaceInput = input.getInterfaceInput()
if interfaceInput:
input = interfaceInput
return input.getNamePath(), interfaceInput
return inputPath, None
def reflectStage(shader, doc, filterStage='pixel', filterBlock='Public'):
'''
Scan through each stage of a shader and get the uniform blocks for each stage.
For each block, extract out some desired information
'''
reflectionStages = []
if not shader:
return
for i in range(0, shader.numStages()):
stage = shader.getStage(i)
if stage:
print('Get Stage:', stage.getName())
if filterStage and filterStage not in stage.getName():
continue
stageName = stage.getName()
if len(stageName) == 0:
continue
reflectionStage = dict()
theBlocks = stage.getUniformBlocks()
if len(theBlocks) == 0:
print(f'stage: {stageName} has no uniform blocks')
for blockName in stage.getUniformBlocks():
block = stage.getUniformBlock(blockName)
print('Scan block: ', blockName, block)
if filterBlock and filterBlock not in block.getName():
#print('--------- skip block: ', block.getName())
continue
if not block.getName() in reflectionStage:
reflectionStage[block.getName()] = []
reflectionBlock = reflectionStage[block.getName()]
for shaderPort in block:
variable = shaderPort.getVariable()
value = shaderPort.getValue().getValueString() if shaderPort.getValue() else '<NONE>'
origPath = shaderPort.getPath()
path, interfaceInput = getPortPath(shaderPort.getPath(), doc)
if not path:
path = '<NONE>'
else:
if path != origPath:
path = origPath + ' --> ' + path
type = shaderPort.getType().getName()
unit = shaderPort.getUnit()
colorspace = ''
if interfaceInput:
colorspace = interfaceInput.getColorSpace()
else:
colorspace = shaderPort.getColorSpace()
#print('add uniform: ', variable, value, type, path, unit, colorspace)
portEntry = [ variable, value, type, path, unit, colorspace ]
#print('add port to block: ', portEntry)
reflectionBlock.append(portEntry)
if len(reflectionBlock) > 0:
reflectionStage[block.getName()] = reflectionBlock
if len(reflectionStage) > 0:
reflectionStages.append((stageName, reflectionStage))
return reflectionStages
if shader:
# Examine public uniforms first
stages = reflectStage(shader, doc, 'pixel', 'Public')
if stages:
for stage in stages:
for block in stage[1]:
log = '<h4>Stage "%s". Block: "%s"</h4>\n\n' % (stage[0], block)
log += '| Variable | Value | Type | Path | Unit | Colorspace |\n'
log += '| --- | --- | --- | --- | --- | --- |\n'
for entry in stage[1][block]:
log += '| %s | %s | %s | %s | %s | %s |\n' % (entry[0], entry[1], entry[2], entry[3], entry[4], entry[5])
log += '\n'
display_markdown(log, raw=True)
Get Stage: pixel stage: pixel has no uniform blocks
Downstream Renderables¶
getDownstreamPorts() can be used to traverse downstream from a given Node. With the current release this does not work with NodeGraphs so custom logic is used instead which calls into getMatchingPorts() on a document.
def getDownstreamPorts(nodeName):
downstreamPorts = []
for port in doc.getMatchingPorts(nodeName):
#print('- check port:', port)
#print('- Compare: ', port.getConnectedNode().getName(), ' vs ', nodeName)
#if port.getConnectedNode().getName() == nodeName:
downstreamPorts.append(port)
return downstreamPorts
getMatchingPorts() should return all ports in the document which reference a given node. Again there is an issue with the current release that this will not find any matches when a nodegraph is referenced by a port. For this example a custom build was used which addresses this issue.
A wrapper utility called getDownStreamNodes() is written to perform downstream traversal starting from a node. It returns ports and corresponding nodes as well as what is considered to be "renderable". This is akin logic found in findRenderableElements() but instead will only look at nodes connected downstream from a node.
"Renderable" is considered to be
- Unconnected
outputports - Shaders (
surfaceshaderandvolumeshadernodes) and - Materials (
materialnode)
from collections import OrderedDict
def getDownstreamNodes(node, foundPorts, foundNodes, renderableElements,
renderableTypes = ['material', 'surfaceshader', 'volumeshader']):
"""
For a given "node", traverse downstream connections until there are none to be found.
Along the way collect a list of ports and corresponding nodes visited (in order), and
a list of "renderable" elements.
"""
testPaths = set()
testPaths.add(node.getNamePath())
while testPaths:
nextPaths = set()
for path in testPaths:
testNode = doc.getDescendant(path)
#print('test node:', testNode.getName())
ports = []
if testNode.isA(mx.Node):
ports = testNode.getDownstreamPorts()
else:
ports = getDownstreamPorts(testNode.getName())
for port in ports:
downNode = port.getParent()
downNodePath = downNode.getNamePath()
if downNode and downNodePath not in nextPaths: #and downNode.isA(mx.Node):
foundPorts.append(port.getNamePath())
if port.isA(mx.Output):
renderableElements.append(port.getNamePath())
nodedef = downNode.getNodeDef()
if nodedef:
nodetype = nodedef.getType()
if nodetype in renderableTypes:
renderableElements.append(port.getNamePath())
foundNodes.append(downNode.getNamePath())
nextPaths.add(downNodePath)
testPaths = nextPaths
def examineNodes(nodes):
"""
Traverse downstream for a set of nodes to find information
Returns the set of common ports, nodes, and renderables found
"""
commonPorts = []
commonNodes = []
commonRenderables = []
for node in nodes:
foundPorts = []
foundNodes = []
renderableElements = []
getDownstreamNodes(node, foundPorts, foundNodes, renderableElements)
foundPorts = list(OrderedDict.fromkeys(foundPorts))
foundNodes = list(OrderedDict.fromkeys(foundNodes))
renderableElements = list(OrderedDict.fromkeys(renderableElements))
#print('Traverse downstream from node: ', node.getNamePath())
#print('- Downstream ports:', ', '.join(foundPorts))
#print('- Downstream nodes:', ', '.join(foundNodes))
#print('- Renderable elements:', ', '.join(renderableElements))
commonPorts.extend(foundPorts)
commonNodes.extend(foundNodes)
commonRenderables.extend(renderableElements)
commonPorts = list(OrderedDict.fromkeys(commonPorts))
commonNodes = list(OrderedDict.fromkeys(commonNodes))
commonRenderables = list(OrderedDict.fromkeys(commonRenderables))
return commonPorts, commonNodes, commonRenderables
nodegraph = doc.getChild('NG_marble1')
nodes = [nodegraph.getChild('obj_pos'), nodegraph.getChild('scale_pos')]
commonPorts, commonNodes, commonRenderables = examineNodes(nodes)
display_markdown('Common downstream:', raw=True)
display_markdown(' - Common downstream ports: [ ' + ', '.join(commonPorts) + ' ]', raw=True)
display_markdown(' - Common downstream nodes: [ ' + ', '.join(commonNodes) + ' ]', raw=True)
display_markdown(' - Common renderable elements: [ ' + ', '.join(commonRenderables) + ' ]', raw=True)
Common downstream:
- Common downstream ports: [ NG_marble1/add_xyz/in1, NG_marble1/scale_pos/in1, NG_marble1/scale_xyz/in1, NG_marble1/noise/position, NG_marble1/sum/in1, NG_marble1/scale_noise/in1, NG_marble1/sum/in2, NG_marble1/sin/in, NG_marble1/scale/in1, NG_marble1/bias/in1, NG_marble1/power/in1, NG_marble1/color_mix/mix, NG_marble1/out, SR_marble1/base_color, Marble_3D/surfaceshader ]
- Common downstream nodes: [ NG_marble1/add_xyz, NG_marble1/scale_pos, NG_marble1/scale_xyz, NG_marble1/noise, NG_marble1/sum, NG_marble1/scale_noise, NG_marble1/sin, NG_marble1/scale, NG_marble1/bias, NG_marble1/power, NG_marble1/color_mix, NG_marble1, SR_marble1, Marble_3D ]
- Common renderable elements: [ NG_marble1/out, SR_marble1/base_color, Marble_3D/surfaceshader ]
The Marble graph is shown below for reference:
Sampling Graph Nodes¶
Given the ability to traverse downstream from a node, it is possible to produce code just a given node or the upstream subgraph rooted at a given node. If a non-surface shader or material node is used to generate from then only that nodes could will be considered.
To generate code for the entire upstream graph the node needs to have a downstream root which is either a shader or a material.
As of version 1.38.7, the easiest way to do this is to create a temporary convert node to route the output type to a downstream surface shader.
For example a convert from color to surfaceshader can be used
import mtlxutils.mxnodegraph as mxg
for nodePath in commonNodes:
node = doc.getDescendant(nodePath)
if not node:
continue
if node.isA(mx.NodeGraph):
outputs = node.getOutputs()
for output in outputs:
outputPath = output.getNamePath()
if outputPath in commonRenderables:
node = output
nodePath = outputPath
else:
convertNode = None
#parent = node.getParent()
#convertNode = mxg.MtlxNodeGraph.addNode(parent, 'ND_convert_' + node.getType() + '_surfaceshader', 'convert_' + node.getName())
#if convertNode:
# mxg.MtlxNodeGraph.connectNodeToNode(convertNode, 'in', node, '')
shaderName = mx.createValidName(nodePath)
try:
shader = shadergen.generate(shaderName, node, context)
except mx.Exception as err:
print('Shader generation errors:', err)
if shader:
pixelSource = shader.getSourceCode(mx_gen_shader.PIXEL_STAGE)
text = '<details><summary>Code For: "' + nodePath + '"</summary>\n\n' + '```cpp\n' + pixelSource + '```\n' + '</details>\n'
display_markdown(text , raw=True)
else:
print('Failed to generate code for shader "%s" code from node "%s"' % (shaderName, nodeName))
if convertNode:
nodePath = convertNode.getNamePath()
shaderName = mx.createValidName(nodePath)
try:
shader = shadergen.generate(shaderName, convertNode, context)
except mx.Exception as err:
print('Shader generation errors:', err)
if shader:
pixelSource = shader.getSourceCode(mx_gen_shader.PIXEL_STAGE)
text = '<details><summary>Convert Code For: "' + nodePath + '"</summary>\n\n' + '```cpp\n' + pixelSource + '```\n' + '</details>\n'
display_markdown(text , raw=True)
else:
print('Failed to generate code for shader "%s" code from node "%s"' % (shaderName, nodeName))
Code For: "NG_marble1/add_xyz"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_add_xyz
(
float3 in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, in2);
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(add_xyz_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/scale_pos"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_scale_pos
(
float in2 = 1.000000
[[
materialx::core::origin("NG_marble1/scale_pos/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float3 scale_pos_out = obj_pos_out * in2;
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(scale_pos_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/scale_xyz"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_scale_xyz
(
float in2 = 1.000000
[[
materialx::core::origin("NG_marble1/scale_xyz/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float scale_xyz_out = add_xyz_out * in2;
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(scale_xyz_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/noise"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_noise
(
float amplitude = 1.000000
[[
materialx::core::origin("")
]],
int octaves = 3
[[
materialx::core::origin("NG_marble1/noise/octaves")
]],
float lacunarity = 2.000000
[[
materialx::core::origin("")
]],
float diminish = 0.500000
[[
materialx::core::origin("")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:amplitude, mxp_octaves:octaves, mxp_lacunarity:lacunarity, mxp_diminish:diminish, mxp_position:scale_pos_out);
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(noise_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/sum"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_sum
(
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(sum_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/scale_noise"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_scale_noise
(
float in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * in2;
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(scale_noise_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/sin"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_sin
(
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(sin_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/scale"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_scale
(
float in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * in2;
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(scale_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/bias"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_bias
(
float in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + in2;
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(bias_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/power"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_power
(
float in2 = 1.000000
[[
materialx::core::origin("NG_marble1/power/in2")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
float bias_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + bias_in2;
float power_out = math::pow(bias_out, in2);
float3 displacement__ = float3(0.0);
color finalOutput__ = mk_color3(power_out);
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/color_mix"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_color_mix
(
color fg = color(0.000000, 0.000000, 0.000000)
[[
materialx::core::origin("NG_marble1/color_mix/fg")
]],
color bg = color(0.000000, 0.000000, 0.000000)
[[
materialx::core::origin("NG_marble1/color_mix/bg")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
float bias_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]],
float power_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/noise_power")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + bias_in2;
float power_out = math::pow(bias_out, power_in2);
color color_mix_out = math::lerp(bg, fg, power_out);
float3 displacement__ = float3(0.0);
color finalOutput__ = color_mix_out;
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "NG_marble1/out"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
export material NG_marble1_out
(
color base_color_1 = color(0.800000, 0.800000, 0.800000)
[[
materialx::core::origin("")
]],
color base_color_2 = color(0.100000, 0.100000, 0.300000)
[[
materialx::core::origin("")
]],
float noise_scale_1 = 6.000000
[[
materialx::core::origin("")
]],
float noise_scale_2 = 4.000000
[[
materialx::core::origin("")
]],
float noise_power = 3.000000
[[
materialx::core::origin("")
]],
int noise_octaves = 3
[[
materialx::core::origin("")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
float bias_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * noise_scale_2;
float scale_xyz_out = add_xyz_out * noise_scale_1;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + bias_in2;
float power_out = math::pow(bias_out, noise_power);
color color_mix_out = math::lerp(base_color_1, base_color_2, power_out);
float3 displacement__ = float3(0.0);
color finalOutput__ = color_mix_out;
}
in material
(
surface: material_surface(
emission : material_emission(
emission : df::diffuse_edf(),
intensity : finalOutput__ * math::PI,
mode : intensity_radiant_exitance
)
),
geometry: material_geometry(
displacement : displacement__
)
);
Code For: "SR_marble1"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
color NG_convert_float_color3
(
float in1 = 0.000000
)
{
color combine_out = color( in1,in1,in1 );
return combine_out;
}
material NG_standard_surface_surfaceshader_100
(
float base = 0.800000,
color base_color = color(1.000000, 1.000000, 1.000000),
float diffuse_roughness = 0.000000,
float metalness = 0.000000,
float specular = 1.000000,
color specular_color = color(1.000000, 1.000000, 1.000000),
float specular_roughness = 0.200000,
float specular_IOR = 1.500000,
float specular_anisotropy = 0.000000,
float specular_rotation = 0.000000,
float transmission = 0.000000,
color transmission_color = color(1.000000, 1.000000, 1.000000),
float transmission_depth = 0.000000,
color transmission_scatter = color(0.000000, 0.000000, 0.000000),
float transmission_scatter_anisotropy = 0.000000,
float transmission_dispersion = 0.000000,
float transmission_extra_roughness = 0.000000,
float subsurface = 0.000000,
color subsurface_color = color(1.000000, 1.000000, 1.000000),
color subsurface_radius = color(1.000000, 1.000000, 1.000000),
float subsurface_scale = 1.000000,
float subsurface_anisotropy = 0.000000,
float sheen = 0.000000,
color sheen_color = color(1.000000, 1.000000, 1.000000),
float sheen_roughness = 0.300000,
float coat = 0.000000,
color coat_color = color(1.000000, 1.000000, 1.000000),
float coat_roughness = 0.100000,
float coat_anisotropy = 0.000000,
float coat_rotation = 0.000000,
float coat_IOR = 1.500000,
float3 coat_normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal()),
float coat_affect_color = 0.000000,
float coat_affect_roughness = 0.000000,
float thin_film_thickness = 0.000000,
float thin_film_IOR = 1.500000,
float emission = 0.000000,
color emission_color = color(1.000000, 1.000000, 1.000000),
color opacity = color(1.000000, 1.000000, 1.000000),
bool thin_walled = false,
float3 normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal()),
float3 tangent = state::transform_vector(state::coordinate_internal, state::coordinate_world, state::texture_tangent_u(0))
)
= let
{
float2 coat_roughness_vector_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_roughness, mxp_anisotropy:coat_anisotropy);
float coat_tangent_rotate_degree_out = coat_rotation * 360.000000;
color metal_reflectivity_out = base_color * base;
color metal_edgecolor_out = specular_color * specular;
float coat_affect_roughness_multiply1_out = coat_affect_roughness * coat;
float tangent_rotate_degree_out = specular_rotation * 360.000000;
float transmission_roughness_add_out = specular_roughness + transmission_extra_roughness;
color subsurface_color_nonnegative_out = math::max(subsurface_color, 0.000000);
float coat_clamped_out = math::clamp(coat, 0.000000, 1.000000);
color subsurface_radius_scaled_out = subsurface_radius * subsurface_scale;
float subsurface_selector_out = float(thin_walled);
color base_color_nonnegative_out = math::max(base_color, 0.000000);
color coat_attenuation_out = math::lerp(color(1.000000, 1.000000, 1.000000), coat_color, coat);
float one_minus_coat_ior_out = 1.000000 - coat_IOR;
float one_plus_coat_ior_out = 1.000000 + coat_IOR;
color emission_weight_out = emission_color * emission;
color opacity_luminance_out = materialx::stdlib_1_9::mx_luminance_color3(opacity);
float3 coat_tangent_rotate_out = materialx::stdlib_1_9::mx_rotate3d_vector3(mxp_in:tangent, mxp_amount:coat_tangent_rotate_degree_out, mxp_axis:coat_normal);
auto artistic_ior_result = materialx::pbrlib_1_9::mx_artistic_ior(mxp_reflectivity:metal_reflectivity_out, mxp_edge_color:metal_edgecolor_out);
float coat_affect_roughness_multiply2_out = coat_affect_roughness_multiply1_out * coat_roughness;
float3 tangent_rotate_out = materialx::stdlib_1_9::mx_rotate3d_vector3(mxp_in:tangent, mxp_amount:tangent_rotate_degree_out, mxp_axis:normal);
float transmission_roughness_clamped_out = math::clamp(transmission_roughness_add_out, 0.000000, 1.000000);
float coat_gamma_multiply_out = coat_clamped_out * coat_affect_color;
float coat_ior_to_F0_sqrt_out = one_minus_coat_ior_out / one_plus_coat_ior_out;
float opacity_luminance_float_out = materialx::stdlib_1_9::mx_extract_color3(opacity_luminance_out, 0);
float3 coat_tangent_rotate_normalize_out = math::normalize(coat_tangent_rotate_out);
float coat_affected_roughness_out = math::lerp(specular_roughness, 1.000000, coat_affect_roughness_multiply2_out);
float3 tangent_rotate_normalize_out = math::normalize(tangent_rotate_out);
float coat_affected_transmission_roughness_out = math::lerp(transmission_roughness_clamped_out, 1.000000, coat_affect_roughness_multiply2_out);
float coat_gamma_out = coat_gamma_multiply_out + 1.000000;
float coat_ior_to_F0_out = coat_ior_to_F0_sqrt_out * coat_ior_to_F0_sqrt_out;
float3 coat_tangent_out = materialx::stdlib_1_9::mx_ifgreater_vector3(coat_anisotropy, 0.000000, coat_tangent_rotate_normalize_out, tangent);
float2 main_roughness_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_affected_roughness_out, mxp_anisotropy:specular_anisotropy);
float3 main_tangent_out = materialx::stdlib_1_9::mx_ifgreater_vector3(specular_anisotropy, 0.000000, tangent_rotate_normalize_out, tangent);
float2 transmission_roughness_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_affected_transmission_roughness_out, mxp_anisotropy:specular_anisotropy);
color coat_affected_subsurface_color_out = math::pow(subsurface_color_nonnegative_out, coat_gamma_out);
color coat_affected_diffuse_color_out = math::pow(base_color_nonnegative_out, coat_gamma_out);
float one_minus_coat_ior_to_F0_out = 1.000000 - coat_ior_to_F0_out;
color emission_color0_out = NG_convert_float_color3(one_minus_coat_ior_to_F0_out);
material metal_bsdf_out = materialx::pbrlib_1_9::mx_conductor_bsdf(mxp_weight:1.000000, mxp_ior:artistic_ior_result.mxp_ior, mxp_extinction:artistic_ior_result.mxp_extinction, mxp_roughness:main_roughness_out, mxp_thinfilm_thickness:thin_film_thickness, mxp_thinfilm_ior:thin_film_IOR, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx);
material transmission_bsdf_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:1.000000, mxp_tint:transmission_color, mxp_ior:specular_IOR, mxp_roughness:transmission_roughness_out, mxp_thinfilm_thickness:0.000000, mxp_thinfilm_ior:1.500000, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_T, mxp_base:material(), mxp_top_weight:1.000000);
material translucent_bsdf_out = materialx::pbrlib_1_9::mx_translucent_bsdf(mxp_weight:1.000000, mxp_color:coat_affected_subsurface_color_out, mxp_normal:normal);
material subsurface_bsdf_out = materialx::pbrlib_1_9::mx_subsurface_bsdf(mxp_weight:1.000000, mxp_color:coat_affected_subsurface_color_out, mxp_radius:subsurface_radius_scaled_out, mxp_anisotropy:subsurface_anisotropy, mxp_normal:normal);
material selected_subsurface_bsdf_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:translucent_bsdf_out, mxp_bg:subsurface_bsdf_out, mxp_mix:subsurface_selector_out);
material diffuse_bsdf_out = materialx::pbrlib_1_9::mx_oren_nayar_diffuse_bsdf(mxp_weight:base, mxp_color:coat_affected_diffuse_color_out, mxp_roughness:diffuse_roughness, mxp_normal:normal, mxp_energy_compensation:false);
material subsurface_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:selected_subsurface_bsdf_out, mxp_bg:diffuse_bsdf_out, mxp_mix:subsurface);
material sheen_layer_out = materialx::pbrlib_1_9::mx_sheen_bsdf(mxp_weight:sheen, mxp_color:sheen_color, mxp_roughness:sheen_roughness, mxp_normal:normal, mxp_base:subsurface_mix_out);
material transmission_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:transmission_bsdf_out, mxp_bg:sheen_layer_out, mxp_mix:transmission);
material specular_layer_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:specular, mxp_tint:specular_color, mxp_ior:specular_IOR, mxp_roughness:main_roughness_out, mxp_thinfilm_thickness:thin_film_thickness, mxp_thinfilm_ior:thin_film_IOR, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_R, mxp_base:transmission_mix_out, mxp_top_weight:1.000000);
material metalness_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:metal_bsdf_out, mxp_bg:specular_layer_out, mxp_mix:metalness);
material thin_film_layer_attenuated_out = materialx::pbrlib_1_9::mx_multiply_bsdf_color3(mxp_in1:metalness_mix_out, mxp_in2:coat_attenuation_out);
material coat_layer_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:coat, mxp_tint:color(1.000000, 1.000000, 1.000000), mxp_ior:coat_IOR, mxp_roughness:coat_roughness_vector_out, mxp_thinfilm_thickness:0.000000, mxp_thinfilm_ior:1.500000, mxp_normal:coat_normal, mxp_tangent:coat_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_R, mxp_base:thin_film_layer_attenuated_out, mxp_top_weight:1.000000);
material emission_edf_out = materialx::pbrlib_1_9::mx_uniform_edf(mxp_color:emission_weight_out);
material coat_tinted_emission_edf_out = materialx::pbrlib_1_9::mx_multiply_edf_color3(mxp_in1:emission_edf_out, mxp_in2:coat_color);
material coat_emission_edf_out = materialx::pbrlib_1_9::mx_generalized_schlick_edf(mxp_color0:emission_color0_out, mxp_color90:color(0.000000, 0.000000, 0.000000), mxp_exponent:5.000000, mxp_base:coat_tinted_emission_edf_out);
material blended_coat_emission_edf_out = materialx::pbrlib_1_9::mx_mix_edf(mxp_fg:coat_emission_edf_out, mxp_bg:emission_edf_out, mxp_mix:coat);
material shader_constructor_out = materialx::pbrlib_1_9::mx_surface(mxp_bsdf: coat_layer_out, mxp_edf: blended_coat_emission_edf_out, mxp_opacity: opacity_luminance_float_out, mxp_thin_walled: false);
}
in material(shader_constructor_out);
export material SR_marble1
(
float base = 1.000000
[[
materialx::core::origin("SR_marble1/base")
]],
float diffuse_roughness = 0.000000
[[
materialx::core::origin("")
]],
float metalness = 0.000000
[[
materialx::core::origin("")
]],
float specular = 1.000000
[[
materialx::core::origin("")
]],
color specular_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
float specular_roughness = 0.100000
[[
materialx::core::origin("SR_marble1/specular_roughness")
]],
float specular_IOR = 1.500000
[[
materialx::core::origin("")
]],
float specular_anisotropy = 0.000000
[[
materialx::core::origin("")
]],
float specular_rotation = 0.000000
[[
materialx::core::origin("")
]],
float transmission = 0.000000
[[
materialx::core::origin("")
]],
color transmission_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
float transmission_depth = 0.000000
[[
materialx::core::origin("")
]],
color transmission_scatter = color(0.000000, 0.000000, 0.000000)
[[
materialx::core::origin("")
]],
float transmission_scatter_anisotropy = 0.000000
[[
materialx::core::origin("")
]],
float transmission_dispersion = 0.000000
[[
materialx::core::origin("")
]],
float transmission_extra_roughness = 0.000000
[[
materialx::core::origin("")
]],
float subsurface = 0.400000
[[
materialx::core::origin("SR_marble1/subsurface")
]],
color subsurface_radius = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
float subsurface_scale = 1.000000
[[
materialx::core::origin("")
]],
float subsurface_anisotropy = 0.000000
[[
materialx::core::origin("")
]],
float sheen = 0.000000
[[
materialx::core::origin("")
]],
color sheen_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
float sheen_roughness = 0.300000
[[
materialx::core::origin("")
]],
float coat = 0.000000
[[
materialx::core::origin("")
]],
color coat_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
float coat_roughness = 0.100000
[[
materialx::core::origin("")
]],
float coat_anisotropy = 0.000000
[[
materialx::core::origin("")
]],
float coat_rotation = 0.000000
[[
materialx::core::origin("")
]],
float coat_IOR = 1.500000
[[
materialx::core::origin("")
]],
float3 coat_normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal())
[[
materialx::core::origin("")
]],
float coat_affect_color = 0.000000
[[
materialx::core::origin("")
]],
float coat_affect_roughness = 0.000000
[[
materialx::core::origin("")
]],
float thin_film_thickness = 0.000000
[[
materialx::core::origin("")
]],
float thin_film_IOR = 1.500000
[[
materialx::core::origin("")
]],
float emission = 0.000000
[[
materialx::core::origin("")
]],
color emission_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
color opacity = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("")
]],
bool thin_walled = false
[[
materialx::core::origin("")
]],
float3 normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal())
[[
materialx::core::origin("")
]],
float3 tangent = state::transform_vector(state::coordinate_internal, state::coordinate_world, state::texture_tangent_u(0))
[[
materialx::core::origin("")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
float bias_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]],
float power_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/noise_power")
]],
color color_mix_fg = color(0.100000, 0.100000, 0.300000)
[[
materialx::core::origin("NG_marble1/base_color_2")
]],
color color_mix_bg = color(0.800000, 0.800000, 0.800000)
[[
materialx::core::origin("NG_marble1/base_color_1")
]]
)
= let
{
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + bias_in2;
float power_out = math::pow(bias_out, power_in2);
color color_mix_out = math::lerp(color_mix_bg, color_mix_fg, power_out);
material SR_marble1_out = NG_standard_surface_surfaceshader_100(base, color_mix_out, diffuse_roughness, metalness, specular, specular_color, specular_roughness, specular_IOR, specular_anisotropy, specular_rotation, transmission, transmission_color, transmission_depth, transmission_scatter, transmission_scatter_anisotropy, transmission_dispersion, transmission_extra_roughness, subsurface, color_mix_out, subsurface_radius, subsurface_scale, subsurface_anisotropy, sheen, sheen_color, sheen_roughness, coat, coat_color, coat_roughness, coat_anisotropy, coat_rotation, coat_IOR, coat_normal, coat_affect_color, coat_affect_roughness, thin_film_thickness, thin_film_IOR, emission, emission_color, opacity, thin_walled, normal, tangent);
material finalOutput__ = SR_marble1_out;
}
in material(finalOutput__);
Code For: "Marble_3D"
mdl 1.9;
import ::df::*;
import ::base::*;
import ::math::*;
import ::state::*;
import ::anno::*;
import ::tex::*;
using ::materialx::core import *;
using ::materialx::sampling import *;
using ::materialx::stdlib_1_9 import *;
using ::materialx::pbrlib_1_9 import *;
color NG_convert_float_color3
(
float in1 = 0.000000
)
{
color combine_out = color( in1,in1,in1 );
return combine_out;
}
material NG_standard_surface_surfaceshader_100
(
float base = 0.800000,
color base_color = color(1.000000, 1.000000, 1.000000),
float diffuse_roughness = 0.000000,
float metalness = 0.000000,
float specular = 1.000000,
color specular_color = color(1.000000, 1.000000, 1.000000),
float specular_roughness = 0.200000,
float specular_IOR = 1.500000,
float specular_anisotropy = 0.000000,
float specular_rotation = 0.000000,
float transmission = 0.000000,
color transmission_color = color(1.000000, 1.000000, 1.000000),
float transmission_depth = 0.000000,
color transmission_scatter = color(0.000000, 0.000000, 0.000000),
float transmission_scatter_anisotropy = 0.000000,
float transmission_dispersion = 0.000000,
float transmission_extra_roughness = 0.000000,
float subsurface = 0.000000,
color subsurface_color = color(1.000000, 1.000000, 1.000000),
color subsurface_radius = color(1.000000, 1.000000, 1.000000),
float subsurface_scale = 1.000000,
float subsurface_anisotropy = 0.000000,
float sheen = 0.000000,
color sheen_color = color(1.000000, 1.000000, 1.000000),
float sheen_roughness = 0.300000,
float coat = 0.000000,
color coat_color = color(1.000000, 1.000000, 1.000000),
float coat_roughness = 0.100000,
float coat_anisotropy = 0.000000,
float coat_rotation = 0.000000,
float coat_IOR = 1.500000,
float3 coat_normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal()),
float coat_affect_color = 0.000000,
float coat_affect_roughness = 0.000000,
float thin_film_thickness = 0.000000,
float thin_film_IOR = 1.500000,
float emission = 0.000000,
color emission_color = color(1.000000, 1.000000, 1.000000),
color opacity = color(1.000000, 1.000000, 1.000000),
bool thin_walled = false,
float3 normal = state::transform_normal(state::coordinate_internal, state::coordinate_world, state::normal()),
float3 tangent = state::transform_vector(state::coordinate_internal, state::coordinate_world, state::texture_tangent_u(0))
)
= let
{
float2 coat_roughness_vector_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_roughness, mxp_anisotropy:coat_anisotropy);
float coat_tangent_rotate_degree_out = coat_rotation * 360.000000;
color metal_reflectivity_out = base_color * base;
color metal_edgecolor_out = specular_color * specular;
float coat_affect_roughness_multiply1_out = coat_affect_roughness * coat;
float tangent_rotate_degree_out = specular_rotation * 360.000000;
float transmission_roughness_add_out = specular_roughness + transmission_extra_roughness;
color subsurface_color_nonnegative_out = math::max(subsurface_color, 0.000000);
float coat_clamped_out = math::clamp(coat, 0.000000, 1.000000);
color subsurface_radius_scaled_out = subsurface_radius * subsurface_scale;
float subsurface_selector_out = float(thin_walled);
color base_color_nonnegative_out = math::max(base_color, 0.000000);
color coat_attenuation_out = math::lerp(color(1.000000, 1.000000, 1.000000), coat_color, coat);
float one_minus_coat_ior_out = 1.000000 - coat_IOR;
float one_plus_coat_ior_out = 1.000000 + coat_IOR;
color emission_weight_out = emission_color * emission;
color opacity_luminance_out = materialx::stdlib_1_9::mx_luminance_color3(opacity);
float3 coat_tangent_rotate_out = materialx::stdlib_1_9::mx_rotate3d_vector3(mxp_in:tangent, mxp_amount:coat_tangent_rotate_degree_out, mxp_axis:coat_normal);
auto artistic_ior_result = materialx::pbrlib_1_9::mx_artistic_ior(mxp_reflectivity:metal_reflectivity_out, mxp_edge_color:metal_edgecolor_out);
float coat_affect_roughness_multiply2_out = coat_affect_roughness_multiply1_out * coat_roughness;
float3 tangent_rotate_out = materialx::stdlib_1_9::mx_rotate3d_vector3(mxp_in:tangent, mxp_amount:tangent_rotate_degree_out, mxp_axis:normal);
float transmission_roughness_clamped_out = math::clamp(transmission_roughness_add_out, 0.000000, 1.000000);
float coat_gamma_multiply_out = coat_clamped_out * coat_affect_color;
float coat_ior_to_F0_sqrt_out = one_minus_coat_ior_out / one_plus_coat_ior_out;
float opacity_luminance_float_out = materialx::stdlib_1_9::mx_extract_color3(opacity_luminance_out, 0);
float3 coat_tangent_rotate_normalize_out = math::normalize(coat_tangent_rotate_out);
float coat_affected_roughness_out = math::lerp(specular_roughness, 1.000000, coat_affect_roughness_multiply2_out);
float3 tangent_rotate_normalize_out = math::normalize(tangent_rotate_out);
float coat_affected_transmission_roughness_out = math::lerp(transmission_roughness_clamped_out, 1.000000, coat_affect_roughness_multiply2_out);
float coat_gamma_out = coat_gamma_multiply_out + 1.000000;
float coat_ior_to_F0_out = coat_ior_to_F0_sqrt_out * coat_ior_to_F0_sqrt_out;
float3 coat_tangent_out = materialx::stdlib_1_9::mx_ifgreater_vector3(coat_anisotropy, 0.000000, coat_tangent_rotate_normalize_out, tangent);
float2 main_roughness_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_affected_roughness_out, mxp_anisotropy:specular_anisotropy);
float3 main_tangent_out = materialx::stdlib_1_9::mx_ifgreater_vector3(specular_anisotropy, 0.000000, tangent_rotate_normalize_out, tangent);
float2 transmission_roughness_out = materialx::pbrlib_1_9::mx_roughness_anisotropy(mxp_roughness:coat_affected_transmission_roughness_out, mxp_anisotropy:specular_anisotropy);
color coat_affected_subsurface_color_out = math::pow(subsurface_color_nonnegative_out, coat_gamma_out);
color coat_affected_diffuse_color_out = math::pow(base_color_nonnegative_out, coat_gamma_out);
float one_minus_coat_ior_to_F0_out = 1.000000 - coat_ior_to_F0_out;
color emission_color0_out = NG_convert_float_color3(one_minus_coat_ior_to_F0_out);
material metal_bsdf_out = materialx::pbrlib_1_9::mx_conductor_bsdf(mxp_weight:1.000000, mxp_ior:artistic_ior_result.mxp_ior, mxp_extinction:artistic_ior_result.mxp_extinction, mxp_roughness:main_roughness_out, mxp_thinfilm_thickness:thin_film_thickness, mxp_thinfilm_ior:thin_film_IOR, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx);
material transmission_bsdf_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:1.000000, mxp_tint:transmission_color, mxp_ior:specular_IOR, mxp_roughness:transmission_roughness_out, mxp_thinfilm_thickness:0.000000, mxp_thinfilm_ior:1.500000, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_T, mxp_base:material(), mxp_top_weight:1.000000);
material translucent_bsdf_out = materialx::pbrlib_1_9::mx_translucent_bsdf(mxp_weight:1.000000, mxp_color:coat_affected_subsurface_color_out, mxp_normal:normal);
material subsurface_bsdf_out = materialx::pbrlib_1_9::mx_subsurface_bsdf(mxp_weight:1.000000, mxp_color:coat_affected_subsurface_color_out, mxp_radius:subsurface_radius_scaled_out, mxp_anisotropy:subsurface_anisotropy, mxp_normal:normal);
material selected_subsurface_bsdf_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:translucent_bsdf_out, mxp_bg:subsurface_bsdf_out, mxp_mix:subsurface_selector_out);
material diffuse_bsdf_out = materialx::pbrlib_1_9::mx_oren_nayar_diffuse_bsdf(mxp_weight:base, mxp_color:coat_affected_diffuse_color_out, mxp_roughness:diffuse_roughness, mxp_normal:normal, mxp_energy_compensation:false);
material subsurface_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:selected_subsurface_bsdf_out, mxp_bg:diffuse_bsdf_out, mxp_mix:subsurface);
material sheen_layer_out = materialx::pbrlib_1_9::mx_sheen_bsdf(mxp_weight:sheen, mxp_color:sheen_color, mxp_roughness:sheen_roughness, mxp_normal:normal, mxp_base:subsurface_mix_out);
material transmission_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:transmission_bsdf_out, mxp_bg:sheen_layer_out, mxp_mix:transmission);
material specular_layer_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:specular, mxp_tint:specular_color, mxp_ior:specular_IOR, mxp_roughness:main_roughness_out, mxp_thinfilm_thickness:thin_film_thickness, mxp_thinfilm_ior:thin_film_IOR, mxp_normal:normal, mxp_tangent:main_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_R, mxp_base:transmission_mix_out, mxp_top_weight:1.000000);
material metalness_mix_out = materialx::pbrlib_1_9::mx_mix_bsdf(mxp_fg:metal_bsdf_out, mxp_bg:specular_layer_out, mxp_mix:metalness);
material thin_film_layer_attenuated_out = materialx::pbrlib_1_9::mx_multiply_bsdf_color3(mxp_in1:metalness_mix_out, mxp_in2:coat_attenuation_out);
material coat_layer_out = materialx::pbrlib_1_9::mx_dielectric_bsdf(mxp_weight:coat, mxp_tint:color(1.000000, 1.000000, 1.000000), mxp_ior:coat_IOR, mxp_roughness:coat_roughness_vector_out, mxp_thinfilm_thickness:0.000000, mxp_thinfilm_ior:1.500000, mxp_normal:coat_normal, mxp_tangent:coat_tangent_out, mxp_distribution:mx_distribution_type_ggx, mxp_scatter_mode:mx_scatter_mode_R, mxp_base:thin_film_layer_attenuated_out, mxp_top_weight:1.000000);
material emission_edf_out = materialx::pbrlib_1_9::mx_uniform_edf(mxp_color:emission_weight_out);
material coat_tinted_emission_edf_out = materialx::pbrlib_1_9::mx_multiply_edf_color3(mxp_in1:emission_edf_out, mxp_in2:coat_color);
material coat_emission_edf_out = materialx::pbrlib_1_9::mx_generalized_schlick_edf(mxp_color0:emission_color0_out, mxp_color90:color(0.000000, 0.000000, 0.000000), mxp_exponent:5.000000, mxp_base:coat_tinted_emission_edf_out);
material blended_coat_emission_edf_out = materialx::pbrlib_1_9::mx_mix_edf(mxp_fg:coat_emission_edf_out, mxp_bg:emission_edf_out, mxp_mix:coat);
material shader_constructor_out = materialx::pbrlib_1_9::mx_surface(mxp_bsdf: coat_layer_out, mxp_edf: blended_coat_emission_edf_out, mxp_opacity: opacity_luminance_float_out, mxp_thin_walled: false);
}
in material(shader_constructor_out);
export material Marble_3D
(
uniform mx_coordinatespace_type geomprop_Nworld_space = mx_coordinatespace_type_world
[[
materialx::core::origin("Nworld")
]],
uniform mx_coordinatespace_type geomprop_Tworld_space = mx_coordinatespace_type_world
[[
materialx::core::origin("Tworld")
]],
uniform int geomprop_Tworld_index = 0
[[
materialx::core::origin("Tworld")
]],
uniform mx_coordinatespace_type obj_pos_space = mx_coordinatespace_type_object
[[
materialx::core::origin("NG_marble1/obj_pos/space")
]],
float3 add_xyz_in2 = float3(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("NG_marble1/add_xyz/in2")
]],
float scale_pos_in2 = 4.000000
[[
materialx::core::origin("NG_marble1/noise_scale_2")
]],
float scale_xyz_in2 = 6.000000
[[
materialx::core::origin("NG_marble1/noise_scale_1")
]],
float noise_amplitude = 1.000000
[[
materialx::core::origin("NG_marble1/noise/amplitude")
]],
int noise_octaves = 3
[[
materialx::core::origin("NG_marble1/noise_octaves")
]],
float noise_lacunarity = 2.000000
[[
materialx::core::origin("NG_marble1/noise/lacunarity")
]],
float noise_diminish = 0.500000
[[
materialx::core::origin("NG_marble1/noise/diminish")
]],
float scale_noise_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/scale_noise/in2")
]],
float scale_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/scale/in2")
]],
float bias_in2 = 0.500000
[[
materialx::core::origin("NG_marble1/bias/in2")
]],
float power_in2 = 3.000000
[[
materialx::core::origin("NG_marble1/noise_power")
]],
color color_mix_fg = color(0.100000, 0.100000, 0.300000)
[[
materialx::core::origin("NG_marble1/base_color_2")
]],
color color_mix_bg = color(0.800000, 0.800000, 0.800000)
[[
materialx::core::origin("NG_marble1/base_color_1")
]],
float SR_marble1_base = 1.000000
[[
materialx::core::origin("SR_marble1/base")
]],
float SR_marble1_diffuse_roughness = 0.000000
[[
materialx::core::origin("SR_marble1/diffuse_roughness")
]],
float SR_marble1_metalness = 0.000000
[[
materialx::core::origin("SR_marble1/metalness")
]],
float SR_marble1_specular = 1.000000
[[
materialx::core::origin("SR_marble1/specular")
]],
color SR_marble1_specular_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/specular_color")
]],
float SR_marble1_specular_roughness = 0.100000
[[
materialx::core::origin("SR_marble1/specular_roughness")
]],
float SR_marble1_specular_IOR = 1.500000
[[
materialx::core::origin("SR_marble1/specular_IOR")
]],
float SR_marble1_specular_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/specular_anisotropy")
]],
float SR_marble1_specular_rotation = 0.000000
[[
materialx::core::origin("SR_marble1/specular_rotation")
]],
float SR_marble1_transmission = 0.000000
[[
materialx::core::origin("SR_marble1/transmission")
]],
color SR_marble1_transmission_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/transmission_color")
]],
float SR_marble1_transmission_depth = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_depth")
]],
color SR_marble1_transmission_scatter = color(0.000000, 0.000000, 0.000000)
[[
materialx::core::origin("SR_marble1/transmission_scatter")
]],
float SR_marble1_transmission_scatter_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_scatter_anisotropy")
]],
float SR_marble1_transmission_dispersion = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_dispersion")
]],
float SR_marble1_transmission_extra_roughness = 0.000000
[[
materialx::core::origin("SR_marble1/transmission_extra_roughness")
]],
float SR_marble1_subsurface = 0.400000
[[
materialx::core::origin("SR_marble1/subsurface")
]],
color SR_marble1_subsurface_radius = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/subsurface_radius")
]],
float SR_marble1_subsurface_scale = 1.000000
[[
materialx::core::origin("SR_marble1/subsurface_scale")
]],
float SR_marble1_subsurface_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/subsurface_anisotropy")
]],
float SR_marble1_sheen = 0.000000
[[
materialx::core::origin("SR_marble1/sheen")
]],
color SR_marble1_sheen_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/sheen_color")
]],
float SR_marble1_sheen_roughness = 0.300000
[[
materialx::core::origin("SR_marble1/sheen_roughness")
]],
float SR_marble1_coat = 0.000000
[[
materialx::core::origin("SR_marble1/coat")
]],
color SR_marble1_coat_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/coat_color")
]],
float SR_marble1_coat_roughness = 0.100000
[[
materialx::core::origin("SR_marble1/coat_roughness")
]],
float SR_marble1_coat_anisotropy = 0.000000
[[
materialx::core::origin("SR_marble1/coat_anisotropy")
]],
float SR_marble1_coat_rotation = 0.000000
[[
materialx::core::origin("SR_marble1/coat_rotation")
]],
float SR_marble1_coat_IOR = 1.500000
[[
materialx::core::origin("SR_marble1/coat_IOR")
]],
float SR_marble1_coat_affect_color = 0.000000
[[
materialx::core::origin("SR_marble1/coat_affect_color")
]],
float SR_marble1_coat_affect_roughness = 0.000000
[[
materialx::core::origin("SR_marble1/coat_affect_roughness")
]],
float SR_marble1_thin_film_thickness = 0.000000
[[
materialx::core::origin("SR_marble1/thin_film_thickness")
]],
float SR_marble1_thin_film_IOR = 1.500000
[[
materialx::core::origin("SR_marble1/thin_film_IOR")
]],
float SR_marble1_emission = 0.000000
[[
materialx::core::origin("SR_marble1/emission")
]],
color SR_marble1_emission_color = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/emission_color")
]],
color SR_marble1_opacity = color(1.000000, 1.000000, 1.000000)
[[
materialx::core::origin("SR_marble1/opacity")
]],
bool SR_marble1_thin_walled = false
[[
materialx::core::origin("SR_marble1/thin_walled")
]]
)
= let
{
material backsurfaceshader = material();
material displacementshader = material();
float3 geomprop_Nworld_out1 = materialx::stdlib_1_9::mx_normal_vector3(mxp_space:geomprop_Nworld_space);
float3 geomprop_Tworld_out1 = materialx::stdlib_1_9::mx_tangent_vector3(mxp_space:geomprop_Tworld_space, mxp_index:geomprop_Tworld_index);
float3 obj_pos_out = materialx::stdlib_1_9::mx_position_vector3(mxp_space:obj_pos_space);
float add_xyz_out = math::dot(obj_pos_out, add_xyz_in2);
float3 scale_pos_out = obj_pos_out * scale_pos_in2;
float scale_xyz_out = add_xyz_out * scale_xyz_in2;
float noise_out = materialx::stdlib_1_9::mx_fractal3d_float(mxp_amplitude:noise_amplitude, mxp_octaves:noise_octaves, mxp_lacunarity:noise_lacunarity, mxp_diminish:noise_diminish, mxp_position:scale_pos_out);
float scale_noise_out = noise_out * scale_noise_in2;
float sum_out = scale_xyz_out + scale_noise_out;
float sin_out = math::sin(sum_out);
float scale_out = sin_out * scale_in2;
float bias_out = scale_out + bias_in2;
float power_out = math::pow(bias_out, power_in2);
color color_mix_out = math::lerp(color_mix_bg, color_mix_fg, power_out);
material SR_marble1_out = NG_standard_surface_surfaceshader_100(SR_marble1_base, color_mix_out, SR_marble1_diffuse_roughness, SR_marble1_metalness, SR_marble1_specular, SR_marble1_specular_color, SR_marble1_specular_roughness, SR_marble1_specular_IOR, SR_marble1_specular_anisotropy, SR_marble1_specular_rotation, SR_marble1_transmission, SR_marble1_transmission_color, SR_marble1_transmission_depth, SR_marble1_transmission_scatter, SR_marble1_transmission_scatter_anisotropy, SR_marble1_transmission_dispersion, SR_marble1_transmission_extra_roughness, SR_marble1_subsurface, color_mix_out, SR_marble1_subsurface_radius, SR_marble1_subsurface_scale, SR_marble1_subsurface_anisotropy, SR_marble1_sheen, SR_marble1_sheen_color, SR_marble1_sheen_roughness, SR_marble1_coat, SR_marble1_coat_color, SR_marble1_coat_roughness, SR_marble1_coat_anisotropy, SR_marble1_coat_rotation, SR_marble1_coat_IOR, geomprop_Nworld_out1, SR_marble1_coat_affect_color, SR_marble1_coat_affect_roughness, SR_marble1_thin_film_thickness, SR_marble1_thin_film_IOR, SR_marble1_emission, SR_marble1_emission_color, SR_marble1_opacity, SR_marble1_thin_walled, geomprop_Nworld_out1, geomprop_Tworld_out1);
material Marble_3D_out = materialx::stdlib_1_9::mx_surfacematerial(mxp_surfaceshader: SR_marble1_out, mxp_backsurfaceshader: backsurfaceshader, mxp_displacementshader: displacementshader);
material finalOutput__ = Marble_3D_out;
}
in material(finalOutput__);
Building A Custom Traversal Cache¶
- Build a cache with node/nodegraph names -> list of ports referencing them
- Only interested in port mappings for non-implementations so cache can be much smaller than when considering every port element in the standard data library !
# getAncestorOfType not in Python API.
def elementInDefinition(elem):
parent = elem.getParent()
while parent:
if parent.isA(mx.NodeGraph):
if parent.getNodeDef():
#print('Skip elem: ', elem.getNamePath())
return True
return False
else:
parent = parent.getParent()
return False
def getParentGraph(elem):
parent = elem.getParent()
while parent:
if parent.isA(mx.NodeGraph):
return parent
else:
parent = parent.getParent()
return None
portElementMap = dict()
for elem in doc.traverseTree():
if not elem.isA(mx.PortElement):
continue
graph = getParentGraph(elem)
graphName = ''
if graph:
if graph.getNodeDef():
continue
graphName = graph.getNamePath()
nd = elem.getAttribute('nodename')
if nd:
qn = graphName + '/' + elem.getQualifiedName(nd)
if qn not in portElementMap:
portElementMap[qn] = [ elem ]
else:
portElementMap[qn].append( elem )
ng = elem.getAttribute("nodegraph")
if ng:
qng = graphName + '/' + elem.getQualifiedName(ng)
if qng not in portElementMap:
portElementMap[qng] = [ elem ]
else:
portElementMap[qng].append( elem )
for k in portElementMap:
print('Node:', k)
for p in portElementMap[k]:
print(' used by:', p.getNamePath(), 'out:' + p.getAttribute('output') if p.getAttribute('output') else '')
Node: NG_marble1/obj_pos used by: NG_marble1/add_xyz/in1 used by: NG_marble1/scale_pos/in1 Node: NG_marble1/add_xyz used by: NG_marble1/scale_xyz/in1 Node: NG_marble1/scale_pos used by: NG_marble1/noise/position Node: NG_marble1/noise used by: NG_marble1/scale_noise/in1 Node: NG_marble1/scale_xyz used by: NG_marble1/sum/in1 Node: NG_marble1/scale_noise used by: NG_marble1/sum/in2 Node: NG_marble1/sum used by: NG_marble1/sin/in Node: NG_marble1/sin used by: NG_marble1/scale/in1 Node: NG_marble1/scale used by: NG_marble1/bias/in1 Node: NG_marble1/bias used by: NG_marble1/power/in1 Node: NG_marble1/power used by: NG_marble1/color_mix/mix Node: NG_marble1/color_mix used by: NG_marble1/out Node: /NG_marble1 used by: SR_marble1/base_color out:out used by: SR_marble1/subsurface_color out:out Node: /SR_marble1 used by: Marble_3D/surfaceshader